论文精读(二)
FreeTensor: A Free-Form DSL with Holistic Optimizations for Irregular Tensor Programs
题目和作者
- 关键概念
- Free-Form
- DSL
- Holistic Optimizations
- Irregular Tensor
- 唐适之
摘要
- 需求:基于算子的深度学习框架在面对不规则张量时会产生大量冗余的内存访问
- 贡献:提出了 FreeTensor,一个形式自由的领域特定语言,支持细粒度的控制流来避免处理不规则张量时冗余的内存访问;支持 CPU 和 GPU
- 实验:不微分,比现存的张量程序框架最多快 5.1 倍(平均 2.08 倍);微分,最多快 127.74 倍(平均 36.26 倍)
简介
- 需求
- 现状:张量被广泛使用,现存的张量程序框架大多封装张量操作作为算子,大多数优化在算子内部完成,用户对张量中的所有元素应用同一个算子,然后把多个算子串联起来形成一个程序,算子经各家算子库被高度手工优化
- 变化:这些基于算子的框架能覆盖大部分的程序,但是最近随着模型越来越大,有倾向于只计算部分张量来节省计算的趋势,基于算子的框架会来回变换张量,导致大量冗余的内存访问
- 例子:Longformer
不是太懂- Longformer 是 Transformer 的一个变种,为解决 Transformer 不能处理长序列的问题,引入了滑动窗口注意力
- 现有框架的实现:填充边界,滑动窗口复制张量为矩阵,进行矩阵乘
- 实际上就是个很简单的滑动乘加操作,没必要削足适履,弄一个矩阵乘出来,进行很多张量复制操作,这产生大量冗余的内存访问
- 不规则张量程序 vs 传统张量程序
- 需要细粒度操作
- 需要算子融合
- 各框架自定义算子现状
- JAX & PyTorchPyTorch:vmap 支持针对张量的部分迭代操作,但迭代应该是依赖无关的(可以调换循环先后顺序?)
- TVM:必须是完美的嵌套循环
- Free-Form
- 如果框架的 API 不好用,那程序员可以直接写 Python/C++ 实现,即形式自由 Free-Form
- 但这样的手工优化操作需要大量的专业知识和人力,此外,自动微分的处理使工作更艰难
- Julia 能用来处理张量和自动微分,但是很难优化
- 解决方案:FreeTensor
- 引入细粒度的张量算子,同时保持张量作为一等公民
- 通过多面体自动分析依赖关系
- 优化:并行化,循环变换,内存层级变换
- 支持自动微分,需要平衡存储或重计算
- 贡献
- 提出了自由形式的领域特定语言,FreeTensor,支持细粒度的算子内操作
- 不同体系上的整套优化和实现
- 高效的自动微分
- 快
背景和动机
- 背景内容基本同简介
- 动机/例子:SubdivNet
- 网状图卷积中的\(\sum_j|e_j-e_{j+1}|\)的计算
- Pytorch 的实现:复制矩阵,重排裁剪矩阵,矩阵减&求绝对值,最后求和
- 相邻的特征向量只对中心面的计算有贡献,但每个中心面的计算都会预取所有的特征向量,或者说矩阵减的过程实际只有一行有意义,这产生大量冗余的内存访问
- 为实现细粒度算子操作控制流的挑战
- 复杂的控制流和数据依赖阻碍了潜在的代码优化
- 复杂的控制流下如何实现高效自动微分
- 抓个虫:论文 Figure3(b) 中的代码应该是
n_feats,而不是in_feats?
自由形式的领域特定语言
张量作为一等公民
张量定义
- 张量是主要类型!张量是 N 维张量,标量是0维张量!
- 张量被存储在紧凑的内存布局中
- 张量的形状在被创建后就是不可变的
- 张量间没有重叠,或者说,是按值复制的
张量索引
- 支持类 Numpy 式索引
粒度透明张量算子
- 例子:Longformer
- FreeTensor 自带通过 FreeTensor 实现的算子库 libop,内含常见张量算子,这些算子都会被全部内联
维度自由编程
- 张量的维度属性得到了很好的支持
- 表示计算可以用嵌套循环,也可以用有限递归;递归会在编译时被展开为嵌套循环
生成高性能代码
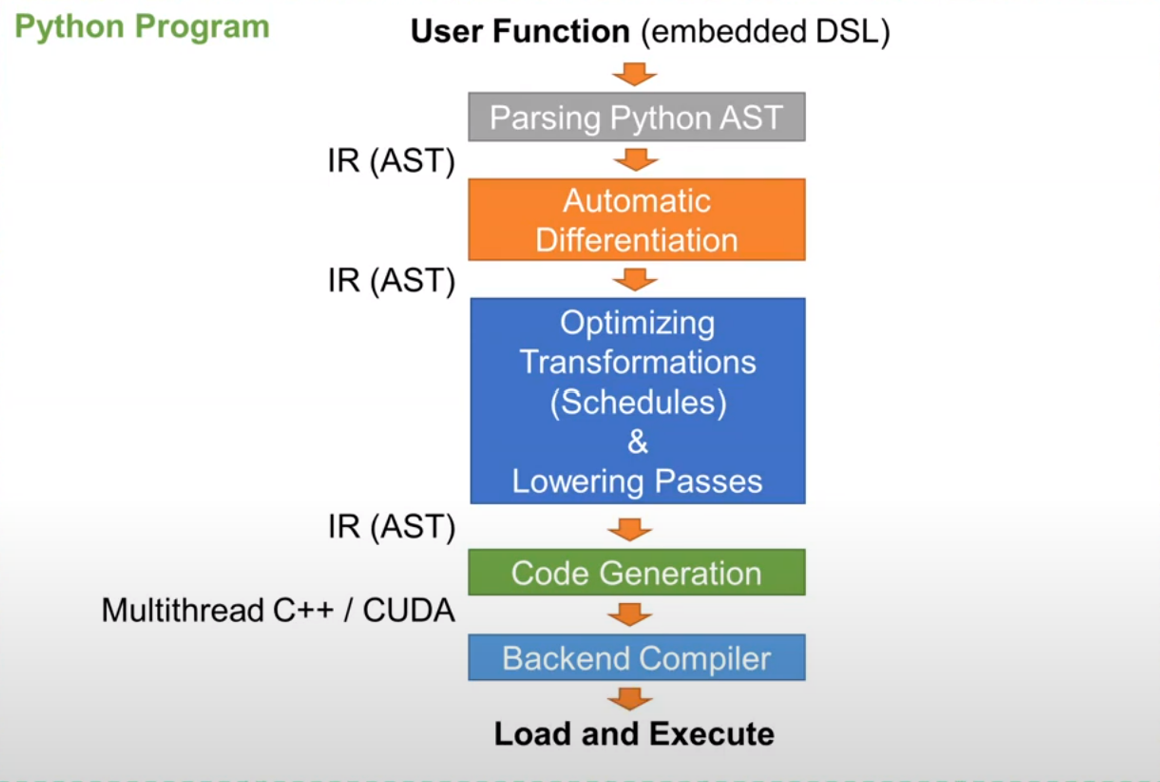
- IR:堆叠作用域 AST
- TensorDef node
- 堆叠作用域限制的好处
- 变换 AST 不破坏分配/释放空间操作对
- 限制张量的生存周期,可以消除依赖帮助依赖分析
没懂堆叠作用域怎么用的
维度自由编程的程序特化分析
- 主要分析递归如何被自动展开为嵌套循环
- 前提:编译时,所有的张量维度都是已知的,递归结束判断基于张量维度
- 实现:不断利用递归进行内联直至最底层
依赖可感知变换
- 细粒度算子操作引入了数据依赖问题,在代码变换前先执行依赖分析
- FreeTensor 在语句实例级别进行数据依赖分析,注意不是语句级别,这意味着传统的数据流图级分析是不够的
- 多面体解算器自动分析数据依赖,这里使用了 isl
- 每个内存访问都被定义为从迭代空间带数组索引空间的一次映射
- 例子:循环重排,并行化变换,内存布局变换,内存层级变换
- 基于规则的启发式变换调度
- 实现了6个 Pass:自动融合、自动向量化、自动并行化、自动内存类型、自动使用库、自动循环展开
- 默认全部调用,用户可以重载或手动应用其它变换,未来将实现类似 Ansor 的基于机器学习的变换策略方案
- 还有一些优化,e.g.,常量替换
- 还进行了一些后端特定后处理
- 最后从 AST 生成 OpenMP 或 CUDA 代码,由 gcc/nvcc 进一步优化,FreeTensor 函数会被编译为动态链接库,可以被 Python 调用
自动微分
- 自动微分:根据原始程序自动生成梯度程序,梯度程序包含前向传播和反向传播
- 前向传播:计算网络输出,同时保存中间变量
- 反向传播:计算梯度并重新使用中间变量
- 自动微分过程作为一个 Pass,生成的结果为 AST,同样可以被优化
- 如果实例化中间张量,反向传播过程会产生大量的内存占用和访问开销;在反向传播过程重新计算是比较快的,因为相关的变量大都在缓存中
- FreeTensor 根据中间变量的版本数决定是否进行实例化
评估
- 平台:CPU、GPU
- 比较:PyTorch,JAX,TVM,Julia,DGL
- 测试集:SubdivNet,Longformer,SoftRas,GAT
- 细节
- 有无自动微分程序分开测试
- 10次热身后测100次取平均
- 随机输入,比较输出
- Pytorch
- 各结果详见论文图片
- 总之效果很好
相关工作
- 基于算子的框架
- Chainer
- PyTorch
- MXNet
- TensorFlow
- JAX
- TVM
- 基于多面体分析的编译器
- Pluto
- PPCG
- CHiLL
- 针对张量的通用语言
- Julia
- Triton
- 自动微分
- 基于算子的框架:基于计算图实现
- 基于 IR 的通用张量程序:Tangent、Myia、Enzyme、Zygote
- FreeTensor 的优势:解决了性能问题
结论
- 提出了针对不规则张量程序,能生成高性能代码,支持自动微分的自由形式领域特定语言 FreeTensor
评论
- 优点
- 发现了深度学习领域中不规则张量的问题
- 解决了依赖可感知变换,自动微分的问题
- 缺点
- Pass 处理得比较粗糙
- 感觉整体实现工作量很大
- 感觉每种框架都去实现一遍测试程序工作量很大,因为框架可能没有合适的 API
- 从计算粒度角度看,通用的张量语言框架粒度小,但对高性能计算或自动微分的支持不太好;而深度学习框架粒度太大,对不规则张量程序的支持不好;FreeTensor 还是从通用张量语言的基础上来解决这个问题,实现一个支持高性能计算和自动微分的通用张量语言框架
- 从其它深度学习框架的角度看,不规则张量程序的问题暴露了多层 IR(主要是图级 IR)的缺点,FreeTensor 中 IR 仅是 AST,没有多层 IR,反而没有信息损失
参考
论文精读(二)
http://example.com/2022/11/03/论文精读(二)/