论文精读(一)
TVM: An Automated End-to-End Optimizing Compiler for Deep Learning
前言
- 我读论文的过程基本按照李沐:如何读论文中的“三遍读论文”方法
- 前段时间看论文主要看综述和读“第一遍”论文,是时候进入下一个阶段了
- 有时候“第一遍”读论文是很久之前了,所以读第三遍时还需要重复“第一遍”和“第二遍”的过程
- 论文精读主要记录“第三遍”的过程和想法
- 按照费曼学习法,读论文的时候基本都模拟自己在做 Pre,或者在教一个小白
题目和作者
- 关键概念
- Compiler
- Deep Learning
- Automated & Optimizing
- End-to-End
- 陈天奇:TVM 作者,XGBoost 作者,MXNet 共同作者
- \(上交\to 华盛顿大学\to CMU\)
摘要
- 需求:随着机器学习的发展,把模型部署到不同设备上的需求越来越大。但是目前的框架优化依赖厂家特定的算子库;部署在新的一些设备平台上需要大量的程序员手动调整。
- 贡献:本文提出了 TVM,为深度学习优化问题提供平台移植性
- TVM 实现了一系列深度学习领域特定优化(计算图级)
- 并且使用基于机器学习的 cost model 来针对不同硬件进行自动低层优化(算子级)
- 实验:在性能较差的 CPU,手机 GPU,GPU上进行了实验,效果拔群;也可以添加新的加速器后端,如 FPGA
- 影响力:开源项目,多家大厂也用
简介
- 需求:略,基本同摘要
- 本文提出了 TVM,一种以当前框架的计算图高层抽象为输入,为多样的设备生成优化过的低层代码的编译器
- 挑战
- 如何高效使用硬件特性和抽象:如张量计算硬件和复杂的内存层级
- 如何处理巨大的优化搜索空间:一个精确的预定义 cost model 需要针对不同硬件手动指定,并且随硬件变化很快
- 解决方案
- 张量表达式:计算/调度分离思想的延续
- 自动程序优化框架:基于机器学习
- 图重写器:充分利用了计算图级和算子级优化
- 贡献
- 定义了跨硬件后端的深度学习模型可移植性优化的主要挑战
- 提出了新的调度原语
- 提出了基于机器学习的自动优化系统
- 端到端的编译优化栈:从各种深度学习框架到各种硬件后端
- 和现有的手动调的深度学习框架中的算子库比,加速比从 1.2 到 3.8 不等
概述
- 如下图
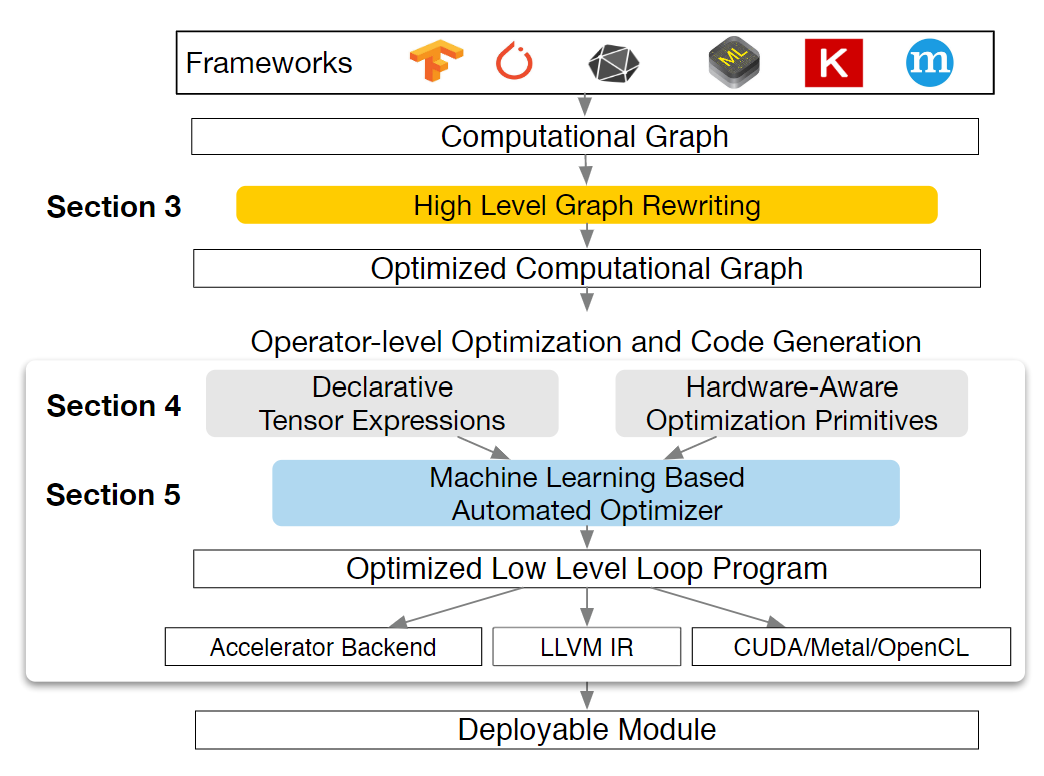
- 支持多种后端部署语言:C++、Java、Python
计算图优化
- 计算图级 IR 和一般的 IR 主要不同在于张量这个核心概念
- TVM 计算图级 IR
- node 代表一个算子操作或者程序输入
- 边代表数据依赖
- 算子融合:融合多个小算子
- 常量折叠:提前算静态常量
- 静态内存分配:预分配储存中间张量的内存
- 数据布局变换:把数据布局变换为后端友好的形式
算子融合
- 减少中间结果的存储,对专用加速器更友好
- 把算子分为四类
- 单射 injective:一对一映射 e.g.,add
- 规约 reduction:e.g.,sum
- 复杂可融合 complex-out-fusable:e.g.,conv2d
- 复杂 opaque:不能被融合 e.g.,sort
- 融合规则
- 单射算子间可以融合
- 规约算子可以融合输入单射算子
- 复杂可融合算子可以融合逐元素操作的算子到输出
数据布局变换
- 常见的数据布局有行优先,列优先,但实际上跑得更快的是更复杂的数据布局
- 实现过程
- 确定当前内存层级更偏好的约束边界
- 通过生产者-消费者模式变换
生成张量操作
- 随着算子数量和后端种类的增加,算子和后端间的优化组合也会增加,我们很难为每一种组合实现一种传统的库函数优化,TVM 通过代码生成解决这个问题
张量表达式和调度空间
- 用于代码生成
- 张量表达式
- 与计算图级 IR 最大的不同是明确了算子的实现,包括 tensor 的计算索引和计算的方式
- 仍然不明确循环的结构,给后端优化留下空间
- 支持常见的算数算子和常见的深度学习算子
- 调度原语:张量/循环级别保证逻辑等价的 pass
- 调度:一系列针对张量/循环的计算的变换
- 构建过程:逐步应用调度原语
- 和 Halide 相比,TVM 引入了更多加速器调度原语
嵌套
嵌套并行协作
- 把大循环拆成嵌套循环,线程可以合并取数据,对加速器的多层内存层级更友好
- 内存范围 memory Scopes
- 可以把一些存储标记为“共享”,线程可以按照不同的并行模式合作加载数据
- 不指定,则默认是“线程本地”
- 需要考虑工作线程的计算依赖和内存同步屏障
- 也方便后续特定代码生成规则的使用 e.g.,GPU
张量化
- 概念类似 SIMD 架构中的向量化
- 把深度学习操作分解为算子操作是一个趋势,如何把它们整合映射到不断变化的后端是一个挑战,这尤其需要可拓展性
- 解决方案:分离硬件指令和它的张量表达声明
- e.g. 增加了 gemm8x8 这个API 层级,张量表达式只管调用,编译器来指定具体由什么硬件指令实现
- 引入了向量化调度原语,它对手工调优也是有帮助的
显式内存延迟隐藏
- 内存延迟隐藏:重叠内存和计算操作以最大化利用资源
- CPU:并发多线程、硬件预取
- GPU:快速的线程束上下文切换
- TPU:DAE(decoupled access-execute)架构,把调度问题交给软件/程序员
- TVM:类似 DAE,引入虚拟调度原语,程序员可以假装后端有多线程支持,TVM 会自动插入同步操作,再合并所有虚拟线程为单指令流,最后由硬件恢复由低级同步所规定的可能的流水线并行性
自动优化
- 调度原语众多,神经网络每层的优化空间都很大,这对系统的自动化能力提出了要求
- 自动调度优化器
- 调度探索器
- 基于机器学习的开销模型
明确调度空间
- 程序员通过 API 设置
- TVM 默认利用张量表达式生成
基于机器学习的开销模型
- 黑盒优化
- 传统开销模型因为系统复杂较困难,而且针对不同的硬件需要不同的开销模型
- 机器学习开销模型
- 编译的 runtime 过程中进行
- 输入:低层代码
- 输出:执行时间
机器学习模型设计选择
- 需要权衡质量和速度
- 和一般的开销模型不同,目标函数不需要是绝对执行时间,而是相对执行时间
- 即不需要知道某配置下的执行时间究竟是多少,只需要知道它比其它配置快即可
- 模型:梯度提升决策树
- 基于 XGBoost
- 特征抽取
- 访存次数
- 每层循环的缓存重用比例
- one-hot 编码的循环
- 尝试神经网络模型:TreeRNN
- 直接分析总结 AST,不经过特征工程
- 结果差不多,但是梯度提升决策树更快
调度探索
- 有了开销模型,进一步需要找到最好的配置
- 因为搜索空间很大,全预测一遍太慢了,这里使用了并行模拟退火算法
基于远程过程调用的分布式设备池
- 负载优化
- 支持端到端的工作,减轻程序员负担
评估
- 核心代码约 50k 行 C++
- 有 Python 和 Java 接口
- 核心问题
- TVM 能在多平台优化深度学习负载吗?
- TVM 相比依赖算子库的各深度学习框架比怎么样?
- TVM 对新兴的深度学习工作支持怎么样?e.g.,深度卷积,低精度运算
- TVM 能支持并优化新的加速器吗?
- 测试平台
- 服务器 GPU
- 嵌入式 GPU
- 嵌入式 CPU
- FPGA
- Benchmark
- ResNet
- MobileNet
- LSTM 语言模型
- DQN
- DCGAN
- 比较
- MxNet
- TensorFlow
- TensorFlow XLA
- 各结果详见论文图片
- 总之效果很好
- 加速比根据算子 breakdown
- FPGA
- VDLA
- 增加该后端约 2k 行 Python
相关工作
- 领域特定语言
- XLA等
- 不成体系,程序员需要大量手动工作
- Halide
- 计算调度分离
- 开销模型
- 算子调度
- 领域特定语言
- TACO
- Weld
- 多面体循环变换
- 领域特定语言
- 自动优化
- ATLAS
- FFTW
- OpenTuner
结论
- 提出了端到端编译栈,解决了不同硬件后端的深度学习优化推理部署问题
- 希望对深度学习系统软硬件系统设计开辟新的机会
评论
- TVM 开山之作,不可不品尝
- 虽然一直都没细读过,但是已经了解了很多机器学习编译和 TVM 的概念,读起来还算轻松
- 编译器是沟通软硬件的桥梁之一,总体上 TVM 对深度学习这个领域的桥梁进行了整合升级
参考
论文精读(一)
http://example.com/2022/10/26/论文精读(一)/