NCCL入门
NCCL
- NCCL(NVIDIA Collective Communications Library)是英伟达的集合通信库,也支持 p2p,是开源的
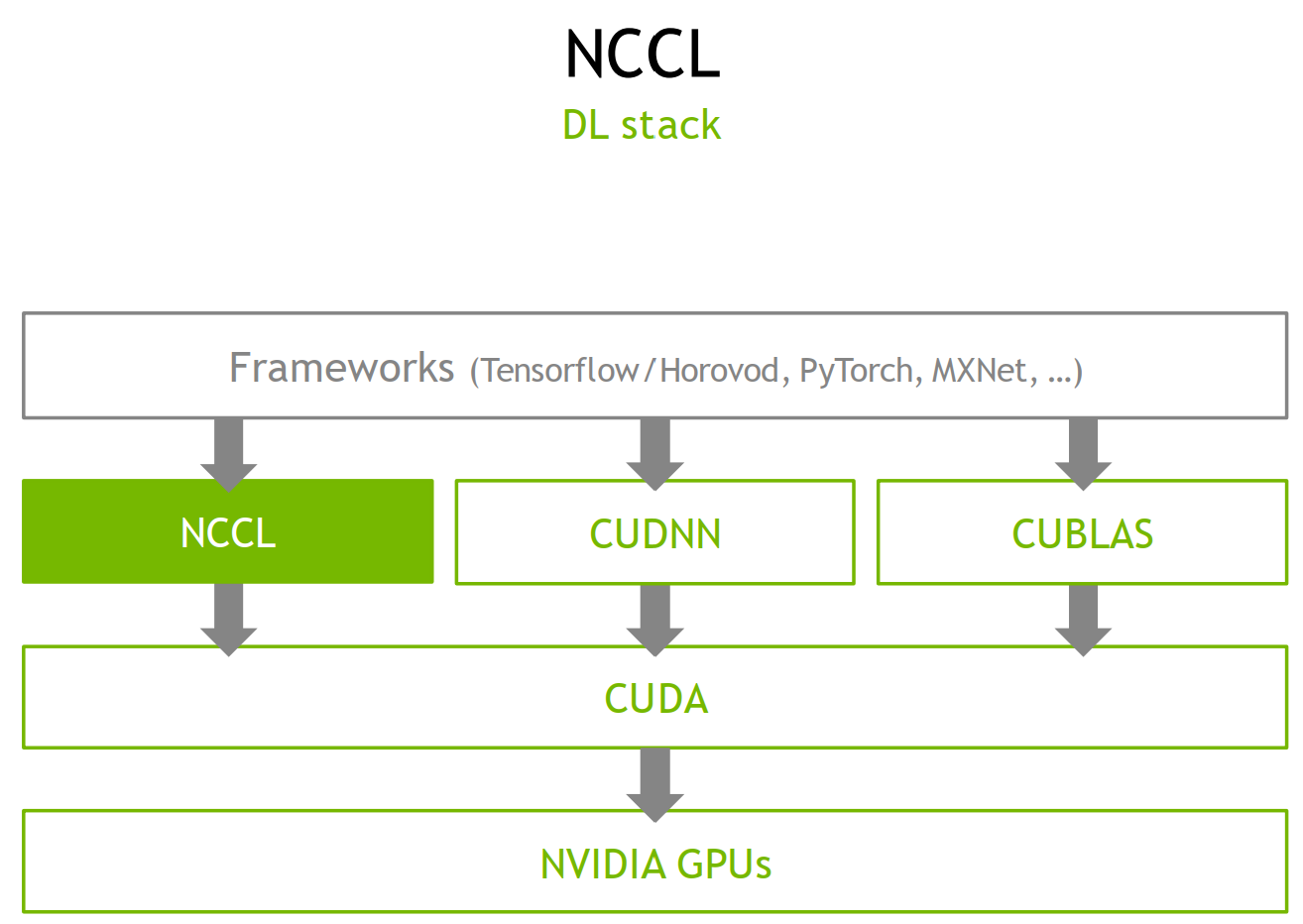
集合通信
- 核心是实现 AllReduce,这是分布式训练最主要的通信方式
- AllReduce
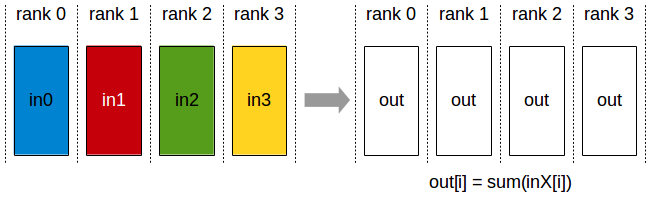
| rank | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| begin | [1,2,3,4] | [5,6,7,8] | [9,10,11,12] | [13,14,15,16] |
| after | [28,32,36,40] | [28,32,36,40] | [28,32,36,40] | [28,32,36,40] |
28=1+5+9+13
32=2+6+10+14
36=3+7+11+15
40=4+8+12+16
- Reduce
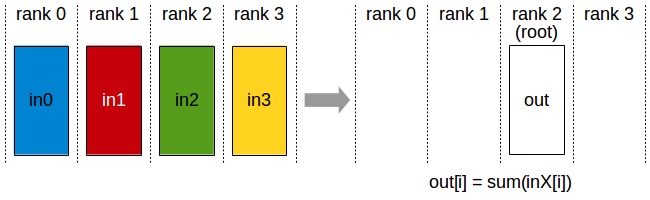
| rank | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| begin | [1,2,3,4] | [5,6,7,8] | [9,10,11,12] | [13,14,15,16] |
| after | / | / | [28,32,36,40] | / |
- Broadcast
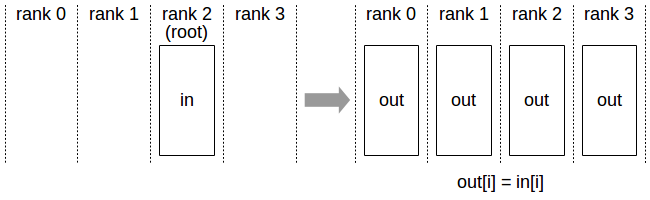
| rank | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| begin | / | / | [28,32,36,40] | / |
| after | [28,32,36,40] | [28,32,36,40] | [28,32,36,40] | [28,32,36,40] |
- ReduceScatter
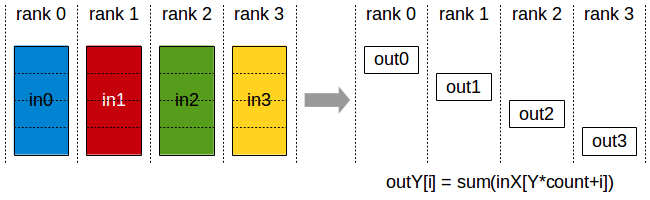
| rank | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| begin | [1,2,3,4] | [5,6,7,8] | [9,10,11,12] | [13,14,15,16] |
| after | [28,/,/,/] | [/,32,/,/] | [/,/,36,/] | [/,/,/,40] |
- AllGather
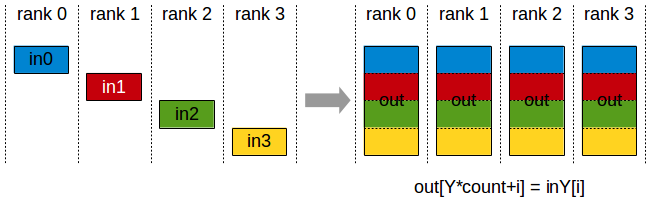
| rank | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| begin | [28,/,/,/] | [/,32,/,/] | [/,/,36,/] | [/,/,/,40] |
| after | [28,32,36,40] | [28,32,36,40] | [28,32,36,40] | [28,32,36,40] |
- 由上面的实例不难看出 AllReduce=Reduce+Broadcast=ReduceScatter+AllGather,在大模型训练中通常使用 ReduceScatter+AllGather
p2p
- 各种复杂 p2p 可以利用
ncclGroupStart,ncclGroupEnd,ncclSend和ncclSend实现
为什么 p2p 需要 ncclGroupStart/ncclGroupEnd?
Point-to-point calls within a group will be blocking until that group of calls completes, but calls within a group can be seen as progressing independently, hence should never block each other. It is therefore important to merge calls that need to progress concurrently to avoid deadlocks.
NCCL vs MPI
- 和 NCCL 相比,MPI(Message Passing Interface)是更普遍的高性能计算通信库
- NCCL 和英伟达硬件绑定地更紧,性能也更好
- 支持 GDRDMA(GPUDirect Remote direct memory access)
- 支持 NVLink
tests
- 官方 NCCL tests
- 多机测试依赖 MPI
- deepspeed 通信测试
- 基于 pytorch,集合通信原语实现不完整
参考
NCCL入门
http://example.com/2024/04/07/NCCL入门/