LLM 结构:从 nanogpt 源码谈起
LLM 结构:从 nanogpt 源码谈起
- 人人都在谈论大模型,可是究竟什么是大模型?这对于研究 LLM 的人是一个基础但是非常重要的问题。本文将以 nanogpt 的源码为例,自顶向下,深入到张量的 shape 分析一个简单但不失普遍性的 LLM 结构。
本文其实比较 NLP,好在搞 SYS 的人只用学一种模型就够了- 代码
- 可视化
nanoGPT
符号表
| 符号 | 含义 | nanoGPT 变量名 | nanaGPT 值 | Llama2-7B | Llama2-7B | Llama2-13B | Llama2-70B |
|---|---|---|---|---|---|---|---|
| s | Sequence length | block_size | 1024 | max_position_embeddings | 4096 | 4096 | 4096 |
| v | Vocabulary size | vocab_size | 50257 | vocab_size | 32000 | 32000 | 32000 |
| L | Number of transformer layers | n_layer | 12 | num_hidden_layers | 32 | 40 | 80 |
| h | Hidden dimension size | n_embd | 768 | hidden_size | 4096 | 5120 | 8192 |
| a | Number of attention heads | n_head | 12 | num_attention_heads | 32 | 40 | 64 |
| Head dimension | h/a | 64 | 128 | 128 | 128 | ||
| i | Dimension of the MLP representations | 4*h | 3072 | intermediate_size | 11008 | 13824 | 28672 |
| t | Tensor-parallel size | 1 | |||||
| b | Microbatch size | batch_size | 12 | ||||
| Minibatch size | 12 | ||||||
| Globalbatch size | 12 |
config
# these make the total batch size be ~0.5M
# 12 batch size * 1024 block size * 5 gradaccum * 8 GPUs = 491,520
batch_size = 12
block_size = 1024
gradient_accumulation_steps = 5 * 8
# this makes total number of tokens be 300B
max_iters = 600000
lr_decay_iters = 600000
# eval stuff
eval_interval = 1000
eval_iters = 200
log_interval = 10
# weight decay
weight_decay = 1e-1class GPTConfig:
block_size: int = 1024
vocab_size: int = 50304 # GPT-2 vocab_size of 50257, padded up to nearest multiple of 64 for efficiency
n_layer: int = 12
n_head: int = 12
n_embd: int = 768
dropout: float = 0.0
bias: bool = True # True: bias in Linears and LayerNorms, like GPT-2. False: a bit better and fastergpt

class GPT(nn.Module):
def __init__(self, config):
super().__init__()
assert config.vocab_size is not None
assert config.block_size is not None
self.config = config
self.transformer = nn.ModuleDict(dict(
wte = nn.Embedding(config.vocab_size, config.n_embd),
wpe = nn.Embedding(config.block_size, config.n_embd),
drop = nn.Dropout(config.dropout),
h = nn.ModuleList([Block(config) for _ in range(config.n_layer)]),
ln_f = LayerNorm(config.n_embd, bias=config.bias),
))
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
def forward(self, idx, targets=None):
device = idx.device
b, t = idx.size()
assert t <= self.config.block_size, f"Cannot forward sequence of length {t}, block size is only {self.config.block_size}"
pos = torch.arange(0, t, dtype=torch.long, device=device) # shape (t)
# forward the GPT model itself
tok_emb = self.transformer.wte(idx) # token embeddings of shape (b, t, n_embd)
pos_emb = self.transformer.wpe(pos) # position embeddings of shape (t, n_embd)
x = self.transformer.drop(tok_emb + pos_emb)
for block in self.transformer.h:
x = block(x)
x = self.transformer.ln_f(x)
if targets is not None:
# if we are given some desired targets also calculate the loss
logits = self.lm_head(x)
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
else:
# inference-time mini-optimization: only forward the lm_head on the very last position
logits = self.lm_head(x[:, [-1], :]) # note: using list [-1] to preserve the time dim
loss = None
return logits, lossdecoder

class Block(nn.Module):
def __init__(self, config):
super().__init__()
self.ln_1 = LayerNorm(config.n_embd, bias=config.bias)
self.attn = CausalSelfAttention(config)
self.ln_2 = LayerNorm(config.n_embd, bias=config.bias)
self.mlp = MLP(config)
def forward(self, x):
x = x + self.attn(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
return x
class CausalSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
assert config.n_embd % config.n_head == 0
# key, query, value projections for all heads, but in a batch
self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd, bias=config.bias)
# output projection
self.c_proj = nn.Linear(config.n_embd, config.n_embd, bias=config.bias)
# regularization
self.attn_dropout = nn.Dropout(config.dropout)
self.resid_dropout = nn.Dropout(config.dropout)
self.n_head = config.n_head
self.n_embd = config.n_embd
self.dropout = config.dropout
# flash attention make GPU go brrrrr but support is only in PyTorch >= 2.0
self.flash = hasattr(torch.nn.functional, 'scaled_dot_product_attention')
if not self.flash:
print("WARNING: using slow attention. Flash Attention requires PyTorch >= 2.0")
# causal mask to ensure that attention is only applied to the left in the input sequence
self.register_buffer("bias", torch.tril(torch.ones(config.block_size, config.block_size))
.view(1, 1, config.block_size, config.block_size))
def forward(self, x):
B, T, C = x.size() # batch size, sequence length, embedding dimensionality (n_embd)
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
q, k, v = self.c_attn(x).split(self.n_embd, dim=2)
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
# causal self-attention; Self-attend: (B, nh, T, hs) x (B, nh, hs, T) -> (B, nh, T, T)
if self.flash:
# efficient attention using Flash Attention CUDA kernels
y = torch.nn.functional.scaled_dot_product_attention(q, k, v, attn_mask=None, dropout_p=self.dropout if self.training else 0, is_causal=True)
else:
# manual implementation of attention
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
att = att.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf'))
att = F.softmax(att, dim=-1)
att = self.attn_dropout(att)
y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
y = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side
# output projection
y = self.resid_dropout(self.c_proj(y))
return y
class MLP(nn.Module):
def __init__(self, config):
super().__init__()
self.c_fc = nn.Linear(config.n_embd, 4 * config.n_embd, bias=config.bias)
self.gelu = nn.GELU()
self.c_proj = nn.Linear(4 * config.n_embd, config.n_embd, bias=config.bias)
self.dropout = nn.Dropout(config.dropout)
def forward(self, x):
x = self.c_fc(x)
x = self.gelu(x)
x = self.c_proj(x)
x = self.dropout(x)
return xself-attention

计算量 & 参数量
- 都主要是 GEMM,这里只看 GEMM
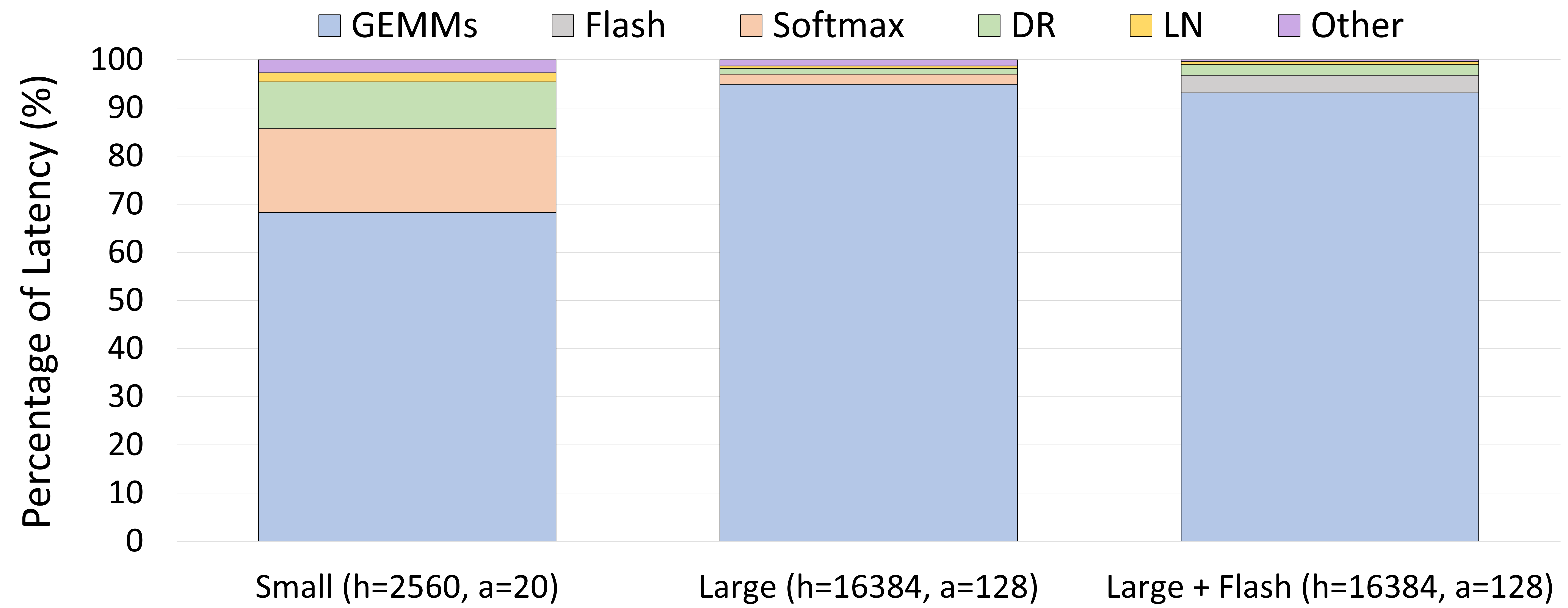
| 序号 | GEMM compute | input shape | another input/参数矩阵 shape | output shape | FLOPs | 参数量 |
|---|---|---|---|---|---|---|
| 1 | QKV Transform | (b,s,h) | (b,h,h*3) | (b,s,h*3) | \(2*b*s*h*(h*3)=6bsh^2\) | \(3h^2\) |
| 2 | Attention Score | (b,a,s,h/a) | (b,a,h/a,s) | (b,a,s,s) | \(2*b*a*s*\frac{h}{a}*s=2bs^2h\) | |
| 3 | Attn over Value | (b,a,s,s) | (b,a,s,h/a) | (b,a,s,h/a) | \(2*b*a*s*s*\frac{h}{a}=2bs^2h\) | |
| 4 | Linear Projection | (b,s,h) | (b,h,h) | (b,s,h) | \(2*b*s*h*h=2bsh^2\) | \(h^2\) |
| 5 | MLP h to 4h | (b,s,h) | (b,h,h*4) | (b,s,h*4) | \(2*b*s*h*(h*4)=8bsh^2\) | \(4h^2\) |
| 6 | MLP 4h to h | (b,s,h*4) | (b,h*4,h) | (b,s,h) | \(2*b*s*(h*4)*h=8bsh^2\) | \(4h^2\) |
| 7 | Linear Output | (b,s,h) | (b,h,v) | (b,s,v) | \(2*b*s*h*v=2bshv\) | \(hv\) |
- decoder 计算量
\[ 6bsh^2+2bs^2h+2bs^2h+2bsh^2+8bsh^2+8bsh^2\\=24bsh^2+4bs^2h\\=24bsh^2(1+\frac{s}{6h}) \]
- gpt 计算量
\[ 24bsh^2(1+\frac{s}{6h})L+2bshv\\\approx 24bsh^2L+2bshv \]
- 参数量
\[ 12h^2L+hv \]
- 常用的经验公式
\[ \frac{计算量}{参数量*token数} \approx\frac{24bsh^2L+2bshv}{(12h^2L+hv)*bs} =2 \]
- 反向经验上计算量是前向的两倍,所以最终的常数是 6,即每 token 的计算量是 6 倍的模型参数量
- 如果开了为了减少激活值显存占用的激活重计算,需要再算一次前向,则常数是 8
- 进一步可以得到大模型训练的时间,以 GPT3-175B 为例,1024xA100,300B tokens,假设 MFU=0.45
\[ \frac{8*300B*175B}{0.45*1024*312TFLOPS} \approx2921340s \approx33.8天 \]
显存占用
训练
- 令 \(\Phi\) 为模型参数量,训练显存占用如下:
| 显存类型 | 数据类型 | 大小(Byte) |
|---|---|---|
| 模型参数 | FP16 | \(2\Phi\) |
| 模型梯度 | FP16 | \(2\Phi\) |
| 优化器状态(Adam) | fp32 | \(12\Phi\) |
- 上述均为模型状态(model states),是主要的显存内容
- 另一类显存内容为剩余状态(residual states),包括激活值(activation)、各种临时缓冲区(buffer)以及无法使用的显存碎片(fragmentation),激活值可以用activation checkpointing 来大大减少,激活值具体占多少显存看策略
- 例:7B 模型训练显存占用约为 \(7B*16Byte=112G\)
推理
- 推理显存占用主要是模型参数和一些额外开销,经验上是其它额外开销是模型参数的\(20\%\)
- 例:7B 模型 FP16 推理显存占用约为 \(7B*2Byte*1.2=16.8G\)
讨论
上述分析比较简单,实际情况:
- 模型超参数和结构不同
- moe
- 各种奇妙的优化技巧
- GEMM TP,实际 GEMM 维度可能变小
- KV cache 占推理显存
- 算子融合
- FlashAttention,会将 3️⃣ 与 softmax 融合以减少访存
- 其它的算子融合情况
- 但是万变不离其宗,已经是 decode 的天下了
- ...
参考
LLM 结构:从 nanogpt 源码谈起
http://example.com/2024/04/14/LLM-结构:从-nanogpt-源码谈起/