操作系统笔记
操作系统
前言
- 网课老师太烂了
每日一问lyb怎么还不退休,所以旁听了陈鹏飞老师的OS课 - 飞哥yyds
OS体系概论
- 指令
- PC(Program Counter):程序计数器,存放下一条指令的地址(的偏移量)
- IR(Instruction register):指令寄存器
- AC(Accumulator):累加器
- 中断
- 提高CPU利用率
- 中断类型:短/中/长
- 多中断处理方式:关闭中断或设置优先级
- 栈:自底向上伸展,地址由高变低
- 存储
- 分层
- 局部性原理
- Cache设计:块大小&置换策略
- I/O
- 可编程I/O:CPU深度参与I/O过程
- 中断驱动的I/O:和CPU是主从关系,主动上报状况,不需要CPU进行扫描
- DMA:单独处理I/O
- 对称多处理机SMP
OS概述
- OS作为软硬件接口
- 四大基本功能:进程管理、内存管理、文件管理、设备管理
- 关键接口
- ISA(Instruction Set architecture):指令集架构,OS与硬件间的接口
- ABI(Application Binary Interface):OS与库间的二进制接口
- API(Application Program Interface):库与应用程序间的接口
- OS软件分类
- Shell
- GUI
- Kernel
- ...
- I/O控制器:daemon,轮询
- 发展历程:串行\(\to\)简单批处理\(\to\)多道批处理/分时系统\(\to\)通用操作系统\(\to\)...
- 串行:卡带,基本上是一个机器
- 简单批处理:为提高CPU利用率,出现了监控程序,或管程,实际上是OS雏形,用户不用和硬件打交道
- 多道批处理:程序交替进行
- 分时系统VS多道批处理:前者最大化CPU利用率,后者最小化用户响应时间
- 进程:操作系统设计的核心
- 运行的程序实例
- OS分配资源的单位
- 多进程可能导致错误
- 进程组件
- 可执行的程序
- 程序的数据
- 程序执行的上下文:OS管理控制进程的内部数据 e.g. 寄存器信息,运行优先级
- 调度和资源管理:多级反馈队列
- 公平性
- 差异性响应
- 效率
- e.g. Mac OS的GCD:线程池,匿名函数
- Windows用户模式进程
- 特殊系统进程
- 服务进程:使用CS架构,实现方法为远程调用。与此不同的是,Linux中核心服务使用共享内存方法。
- 环境子进程
- 用户应用进程
- OS存储管理任务
- 进程隔离
- 自动化内存分配管理
- 支持模块化编程:动态加载模块
- 保护和访问控制
- 长期存储
- 虚拟内存:允许程序以逻辑方式访问存储器,而不用考虑物理内存中的可用空间数量
- 程序员在比物理地址大得多的地址编程
- MMU:将虚存直接转化实地址(物理主存地址)或者磁盘上的虚存地址(再页中断调页进主存,返回新的实地址)
- 段页式存储
- 虚存:在磁盘上的内存
- 和一般磁盘的区别:磁盘按块访问,虚存按页访问
- 信息保护和安全
- 可用性
- 可靠性
- 数据完整性
- 权限:e.g. LSM(Linux Security Module)
- 容错:利用冗余来实现,会付出经济和性能的代价
- 可用性VS可靠性:可用性指发生失效的比例低,是一个概率概念;可靠性指一段连续时间内是否正常运转,一旦发生失效,后续可能都无法运行,是一个积分概念,与发生失效的时间点相关
- 临时性故障VS持久性故障:后者不处理就好不了,前者可能自己好
- 提高冗余的技术:进程隔离,并发控制,虚拟机,检查点和回滚
- 现代OS体系结构方法
- 微内核\(\Leftrightarrow\)宏内核(又分为单体和单体分层)。目前主流的OS都是宏内核,Linux虽然是宏内核,但具有模块化的特性,可以拆解部分内核功能,如安卓的在硬件上的处理。
- 外核:把硬件抽象放在应用层,交给应用自己处理,不分应用态和内核态,特别小,一般只有几M
- 多线程
- 对称多处理
- 分布式OS
- 面向对象:如Windows中大量使用面向对象
- 多核
- 并行粒度:指令,线程,进程
中断&异常&系统调用
- 中断:来自硬件的处理请求,分为主动和被动,又叫外中断
- 异常:当前指令执行失败,又叫内中断
- 系统调用:应用程序向OS发出的服务请求,一般需要陷入(从用户态到内核态)
- 常见的三种接口:Win API、POSIX API、JVM API
- 传参类型:通过寄存器、通过传参数表的地址、通过栈
进程&线程
- 进程元素:ID,状态,优先级,PC,内存指针,上下文数据,I/O状态,记录信息等
- 进程控制块PCB:包含进程元素,由OS创建和管理。
- 分派器:进程切换程序
- 进程状态模型
- 阻塞
- 挂起
- 就绪
- 进程派生
- fork():拷贝父进程的代码和数据,产生新的进程,旧进程仍存活。对于父进程,返回子进程ID,对于子进程,返回0。
- exec():仅保留PID,用新程序的代码和数据改写当前进程映像。
- 进程排队模型
- 多阻塞队列
- 进程映像
- 用户程序
- 用户数据
- 栈
- 属性集合/PCB:包含PSW
- 用户模式与系统(内核/特权)模式
- 进程VS线程
- 线程是轻量级进程
- 进程是资源分配的单位
- 线程是调度分派的单位
- 线程不能脱离进程存在
- 线程模型
- 单线程
- 多线程
- 线程控制块TCB
- 线程的优势
- 创建关闭快
- 切换快:进程切换需要切换到内核态,(用户级)线程不需要
- 通信快:进程通信需要IPC或网络,线程通信可以共享内存
- 线程无挂起态:进程挂起,它的所有线程都被挂起
- 挂起是把资源从内存移到磁盘上,本质上是资源分配,所以线程没有
- 远程过程调用RPC(Remote Process Call)
- 进程间RPC是同步处理的
- 同一个进程的线程间RPC是异步处理的
- 同步:任务按一定顺序执行
- 内核分类
- 用户空间:用户的内存;内核空间:内核的空间。
- 用户级线程ULT(User Level Thread):线程在用户态,所有工作在用户态处理,内核意识不到线程的存在。优势:创建,通信,切换快;不同的应用可以使用不同的线程调度算法。劣势:线程的系统调用需要切换到内核态,不仅阻塞自己,还会阻塞进程所有的线程;对多核的支持比较差,因为OS看不到多线程,只能把CPU分配给进程。
- 内核级线程KLT(Kernel Level Thread):内核可以在细节上管理线程,主要使用线程池。优势:一个线程阻塞不会阻塞同进程的其它线程;对多核支持良好,OS可以分配CPU给线程。劣势:线程切换必须陷入内核,慢;线程创建通信开销较大。
- (Windows使用内核线程,创建线程抽象为API,线程由OS管理。)
- 混合方法:线程的创建调度同步在用户态,多个用户线程会映射到一些内核线程上。又分为一对一,多对一(主流OS),多对多(Solaris)。优点:取用户线程和内核线程的优点。缺点:线程管理复杂,开销大。
- 进程和线程的关系
- 一对一:UNIX
- 一对多:目前的主流OS
- 多对一:云计算场景
- 多对多:略
- 开销数量级上上:进程\(\approx 10\)内核线程,内核线程\(\approx 10\)用户线程
- 线程API标准库
- POSIX Pthreads:可以创建内核态和用户态线程
- Windows:只能创建内核态线程
- Java:JVM对前两者的封装
- 异步/同步线程:
- 异步:父线程异步创建了线程后,即可执行自己的代码
- 同步:父线程异步创建了线程后,需要等待子进程执行玩才可执行自己的代码
- 可在创建线程时通过参数设置
- 线程派生pthread_create():类似fork()
- 纤程(fiber):Windows8+中比线程粒度更小的一个可执行单元,可以理解为一组函数的集合,必须依赖于线程
- 轻量级进程(LWP):是建立在内核之上并由内核支持的用户线程,它是内核线程的高度抽象,每一个轻量级进程都与一个特定的内核线程关联,即混合机制下的一对一模型。内核线程只能由内核管理并像普通进程一样被调度。e.g. Solaris
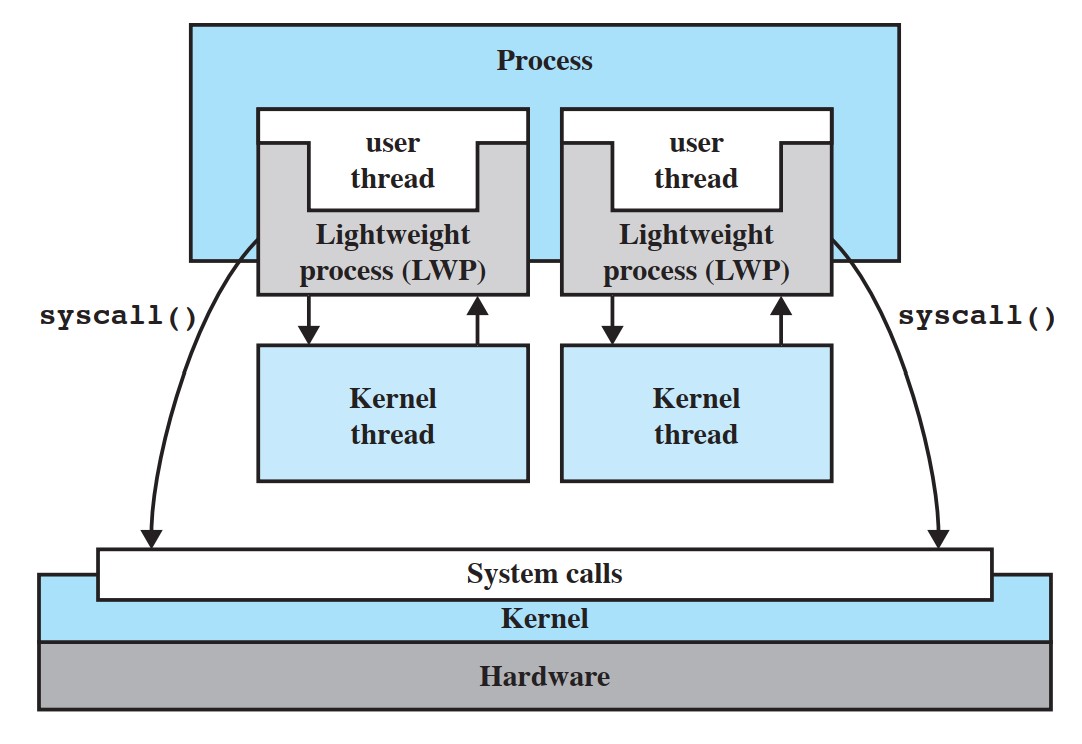
- linux
- 不区分进程和线程的概念,创建clone()
- 命名空间:一种虚拟化技术,内核和用户视角下的结果是不一样的,各自相互隔离。mnt,文件系统相关;pid,线程相关,每个用户有自己独立的pid空间;等等。
- 查看线程命令:ps -e
互斥和同步
- 进程通信
- 共享内存
- 消息传递:套接字等
- 管道
- 信号
- 信号量
- 信号和信号量是触发式传递消息,主要进行同步互斥等;消息传递主要传递大量数据
- 竞争条件:执行结果和程序执行顺序有关
- 同步和互斥的实现
- 硬件
- 禁用中断:单处理器下,代价很高
- 比较交换(机器)指令CAS:原子操作
- Exchange(机器)指令:原子操作,初始全局变量bolt为0,线程keyi为1,只有交换后keyi为0才能进入临界区,执行完后bolt置0
- 特殊机器指令:简单,但是会忙等待,可能饥饿,死锁
- 软件
- 计数信号量(软件实现时)
- 二元信号量(软件实现时)
- 锁
- 条件变量:主要注重线程间,而信号量主要注重进程间,实际上两者基本可以混用
- 管程
- 硬件
- 信号量sem
- 简单版:值
- 复杂版(UNIX):值,最后一个操作进程,等待该信号量的值大于当前值的进程数,等待该信号量的值为0的进程数
- semWait()/P()/Down():sem--,if(sem<0) 自身阻塞
- semSignal()/V()/Up():sem++,if(sem<=0) 通知取消一个线(进)程的阻塞
- 消除了忙等待
- 实现细节上需要关开中断
- 强弱信号量
- 强信号量唤醒阻塞进程使用FIFO
- 弱信号量无唤醒规则
- 实现
- 必须是原子操作
- 硬件实现
- Dekker和Peterson算法
- 管程
- 面向对象的思想,数据和方法都必须通过管程来调用
- 基于条件变量实现
- 存在多条条件变量cwait()队列
- 一次只能有一个进程从队列进入管程,从而实现互斥
- cwait实现
- MESA:V操作后将阻塞进程唤醒,放入就绪队列尾;因为下次被调用时,之前可能经历了多次其它的进程调用,条件可被P操作改变,故判断条件用while。主流实现方式。
- Hasen:V操作后将阻塞进程唤醒,等待当前进程执行完或超时,再进行调度。折中方案。
- Hoare模型:V操作后将阻塞进程唤醒,立即进行调度,有反复进程切换开销,效率比较低;判断条件用if。
- 消息传递
- send
- 阻塞
- 非阻塞
- receive
- 阻塞
- 非阻塞
- 测试消息是否到达(test for arrival)
- 寻址,格式,队列规则
- 消息:有类型的文本
- UNIX系统调用msgsnd,msgrcv
- 每个进程都有一个关联的消息队列,类似信箱
- send
- 管道:环形缓冲区,允许两个进程以生产者-消费者模型进行通信
- FIFO队列,一个进程写,一个进程读
- 含最大字节数,读写不能超过管道大小
- 强制互斥,一次仅允许一个进程访问管道
- 分为匿名管道和命名管道
- 例:Linux中的"|",匿名管道,"ps -e|grep "process_name"",该句表明ps命令(线程)的输出通过管道穿给grep命令(线程)
- 命名管道实际上是一种新的文件类型,是一个FIFO文件
- 共享内存
- 最快
- 虚存中多进程共享的一个公共内存块
- 没有自带互斥机制,需要进程自己处理
- 信号:向一个进程通知发生异步时间的机制
- 具体信号:...
- 具体问题
- 生产者消费者:二元信号量,信号量,管程的具体实现
- 读者写者:读优先,写优先
- UNIX
- 管道
- 消息
- 共享内存
- 信号量
- 信号
- Linux
- 屏障
- 自旋锁:有一套API,进一步有读优先的读写自旋锁
- 信号量
- 用户态信号量,有一套API
- 内核级信号量,不能被用户直接访问,由内核内部函数实现,更高效
- 类型:二值,计数,读写
- 原子操作
- 整数操作:atomic_t及一套API
- 位图操作:通过指针来操作位,同样有一套API
- 注意:要避免编译器错误地优化了对该值的访问
- 整数操作:atomic_t及一套API
- Solaris
- 互斥锁
- 信号量
- 条件变量
- 读写锁
- Windows
- 分派器对象,等待函数
- 临界区:只能用于单进程的线程
- 轻量级读写锁
- 条件变量
- 锁无关操作:硬件或内部实现,具体实现用户透明
- Android
- 连接器Binder:提供轻量级远程过程调用
死锁
- 联合进程图
- 资源
- 可重用资源
- 不可重用资源
- 都可能发生死锁
- 死锁条件
- 互斥
- 占有柄等待
- 非抢占
- 循环等待
- 资源分配图
- 是否成环
- 死锁预防
- 破坏死锁条件
- 策略:一次性分配所有资源;抢占;资源排序。各有优缺点。
- 死锁避免
- 寻找安全路径
- 判断当前进程申请的资源是否会发生死锁,需要知道进程资源需求情况
- 银行家算法
- 优点:无需抢占回滚;缺点:必须申明进程最大资源且是固定不变的,进程间不能有同步要求,占有资源时,进程不能退出
- 死锁检测
- 周期性检测死锁:检测内存读写进行估算
- 死锁检测算法:循环贪心
- 鸵鸟策略,是一种较激进的策略
- 恢复策略:把所有导致死锁的进程全部kill掉/回滚;连续取消进程,直至没有死锁,基于最小代价原则;连续抢占资源直至没有死锁,基于最小代价原则
- 最小代价原则:消耗的CPU最少;输出最少;剩余时间最长;当前分配的资源总量最少;优先级最低
- 具体问题:哲学家就餐问题
- 设置4人的room,仅允许4人进入,避免死锁
- 或者同时拿两个叉
内存管理
- 用户空间
- 如下从高到低有4块空间
- 栈:局部变量
- 栈顶寄存器sp,栈底寄存器bp
- 堆:动态分配的内存
- 数据段&BSS:全局和静态变量
- 在O0优化时,未初始化的变量编译时放在BSS处,并没有真正地分配空间;而初始化的变量在编译时放在数据段,已经分配好了空间。
- ulimit命令查看修改栈/段等的大小
- 超过设置limit和超过物理极限的segmentation fault的错误是两种不同的错误(在limit为unlimited时是一样的)
- 代码和常量:只读
- 基本概念
- 帧/页框:固定长度内存块
- 页:固定长度外存(数据)块
- 段:非固定长度外存(数据)块
- 内存管理需求
- 重定位:程序被换出后很难被换回到原来的内存位置
- 保护
- 共享
- 逻辑组织
- 物理组织
- 内存分区
- 固定:等/非等大小分区,程序太大需要使用覆盖技术,内部碎片多,内存利用率很低
- 具体算法:单/多等待队列。
- 动态
- 放置算法:最佳,最先,上一次(结束位置开始搜索)最先
- 置换算法:伙伴系统Buddy System:只能申请2的幂的空间,方便块的合并,减少外部碎片;Slab:方便分配小内存。
- 简单分页
- 简单分段
- 虚存分页
- 虚存分段
- 固定:等/非等大小分区,程序太大需要使用覆盖技术,内部碎片多,内存利用率很低
- 重定位
- 逻辑地址:和物理地址无关的地址
- 相对地址:以某些地址为基的地址
- 物理/绝对地址:内存实地址
- 重定位的硬件支持
- 基地址寄存器
- 加法器:把基地址和相对地址相加
- 比较器:和边界值比较。过界中断;没过界在内存中找数据
- 边界寄存器
- 分页
- (一级)页大小一般默认4k:页表项大小和虚拟内存相关,大数据情景下经常需要调大,或者使用多级页表(但需要额外内存开销),倒排页表
- 无外部碎片,会产生内部碎片
- 每个进程通过OS都维护一张页表,甚至有多级页表或者倒排页表,页表内有很多关于页的信息
- 分页是透明的,程序员看不到
- 地址转换:映射后拼接
- 页表一般放在主存中,cache中放不下
- 页表中没有页号,页号就是页表偏移量,页表是根据页号顺序存储的
多级页表
- 虚存太大,不能线性存储,而是树形存储
倒排页表
- 页表项大小和主存相关,和虚拟内存无关
- 页号通过hash函数获取页框号
- 使用拉链法处理冲突
- 因为该页表中通过页框号进行索引,所以叫倒排链表
- 快表TLB:页表的cache
- TLB项=页号+页表项,TLB项是无序存储的
- 查找时需要从前往后顺序查找
虚拟内存在一级cache下寻址过程如下
graph LR
1["页号"] ---|TLB find| 2["页框号"]
1 ---|TLB not find| 3["页号"]
2 ---|cache find| 4["ok"]
2 ---|cache not find| 5["页框号"]
5 ---|main memory find| 6["ok"]
5 ---|main memory not find| 7["页框号"]
7 ---|调页| 8["ok"]
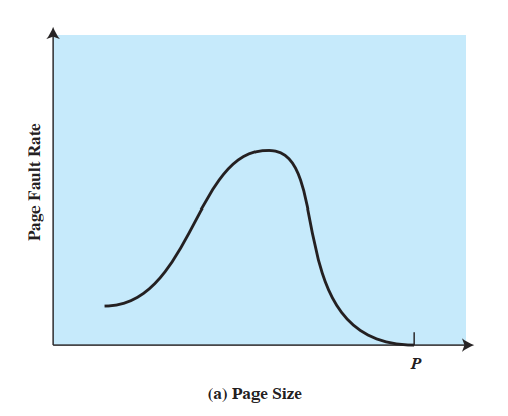
3 ---|page table find| 2页尺寸
- 太小:缺页中断发生概率小,调页开销大(同一块数据没有,本来只需要一次缺页中断,变为了需要多次缺页中断);页表变大,甚至影响页表的存储,严重影响性能
- 太大:缺页中断发生概率小,调页开销大(一次缺页中断就要很久,需要装入很多没用的数据),局部性变差
1 - 挑战
- 大数据:需要更大的页,局部性变差
- 面向对象:对象小,页大,内部碎片很大,需要内存整理技术
- 多线程:影响局部性
页管理策略
- 读取策略:按需,准备
- 放置策略
- 替换策略:最优OPT(仅理论),最近最少使用LRU,先进先出FIFO,时钟Clock;LRU在重复访问元素时需要刷新栈,把该元素放到队列尾,FIFO重复服务时不变;CLOCK循环扫描,元素增加一个访问位,访问位为1不会被替换,但访问位会被置0,指针指向的是即将操作的位
- 页缓存:被置换的页仍然留在内存中
- 驻留集策略
- 清处(回写)策略:按需,预清理
- 并发度策略&&加载控制:并行度太低,内存中进程太少,CPU利用率太低;并行度太高,内存中进程太多,进程切换开销太大;可以监控PFF来调整。
- 基本没有最优策略,需要根据环境处理,有和AI结合应用场景
分段
- 把程序及其相关数据划分到几个部分,即段,每段大小不一,有最大长度
- 无内部碎片,会产生外部碎片
- 每个进程通过OS都维护一张段表,逻辑地址由两部分构成:段号,偏移量
- 分段是需要程序员自己处理的
- 地址转换:映射后相加
- 方便处理增长式的数据结构
GDT(Global Descriptor Table):全局(进程段)描述符表
控制寄存器
- 页表基地址寄存器CR3
- 缺页线性地址寄存器CR2
- 保留寄存器CR1
- 保护模式寄存器CR0
- 虚拟8086寄存器CR4
- 它们均和虚拟内存相关
段页式虚拟内存
- 必须有分页和分段的软硬件支持
- 段进行粗粒度划分,页进行细粒度划分
- 先寻段,再寻页
- 每一个段一个页表
一个精妙的例子

0 - 父子进程的变量pid逻辑地址一模一样,因为fork是完全复制的,它们都把CPU当成独占的,但该地址经过MMU转换后会变成不同的物理地址,所以是不同的变量,一个值为子进程pid,一个为0
系统抖动
- 大部分时间花在交换内存页面,OS效率很低
驻留集RSS
- 内存中页的数量,决定进程的哪些部分放在主存中
- 驻留集管理策略,置换策略
- 管理策略
- 固定分配:一个进程的页框数是固定的
- 可变分配:需要持续评估进程的活动,需要额外开销和硬件支持
- 置换策略
- 局部置换:仅在缺页的进程的驻留集中置换
- 全局置换
- 固定分配+局部置换:需要事先确定分配给该进程的总页框数
- 可变分配+全局置换:大多数OS使用的策略
- 可变分配+局部置换:需要时常评估进程的页框使用情况,增减其页框
工作集WS
- 过去一定虚拟时间(单位)内进程访问的页框的集合,用于评估进程的页框使用情况
- 采样间隔:固定,可变
top命令中的显示
- RES:进程占用的物理内存值,反映了驻留集大小
- VIRT:进程占用的虚拟内存值
- SHR:进程占用的共享内存值
- PR:优先级
- NI:nice值,用户控制的可用来控制调度优先级的参数
保护和共享
- OS通过环状结构实现
- 程序可以访问环内的数据,调用环外的服务
UNIX虚拟内存管理
- 抽象化管理,和硬件解耦(UNIX大多数系统都是如此)
- 内核和用户的内存管理不同,内核仅管理物理内存,用户段页式虚拟存储
- 维护一个可用页框链表,若少于阈值则内核从进程处“偷”一定页框
- 页面置换策略:改进的CLOCK,含两个指针;首次读取访问位置0,再次被访问置1;前指针扫描寻找第一个可用被替换的页,并将其访问位置0;后指针扫描前指针之前扫描过的列表,若该页被置1,这表示它被访问过,需要略过,若该位为0,则替换;扫描窗口(前后指针间距)不能太小,否则很容易抖动。
- 内核内存分派器:懒惰伙伴系统
Linux虚拟内存管理
- 很多地方类似UNIX
- 内核和用户的内存管理不同,内核仅管理物理内存,用户段页式虚拟存储
- 页框的可能拥有者
- 用户进程
- 动态内核数据
- 静态内核数据
- 页缓冲区
- 三级页表:全局页目录表(通过cr3来确定基地址),页中间目录表,页表
- 页面置换策略:改进的CLOCK,置换位8bits,每次被访问增加一位。页有活跃位(考虑一段时间)和被访问位(考虑被访问),在4种状态间跳转。
- 内核内存分派器:Slab,为了适用小内存块
Windows虚拟内存管理
- 和硬件解耦
- 段页式虚拟存储,页大小4K~64K
- 驻留集策略:可变分配+局部范围
调度
- 目标:CPU使用率&&响应时间&&能耗
- 调度类型
- 长程调度:决定将哪个进程加入系统中处理,即在创建和结束间的切换,可控制并发度
- 中程调度:决定将外存中的哪个进程部分或全部送到内存,即换入换出策略,在挂起间切换,可控制存储
- 短程调度:决定从准备队列中选择哪个进程送到CPU执行,即分派策略/CPU调度器,在准备和运行间切换;目标:用户导向,系统导向
- 短程调度标准
- 性能相关:响应时间,周转时间,截止时间,吞吐,使用率,公平性,强制优先级(饥饿解决:优先级降级),资源均衡
- 非性能相关:分为可量化和不可量化,如可预测性
- 老师的故事:科研的领域
- 有评价体系:容易快速成长,容易有结果,但实际上贡献不大,如CV,NLP,DM
- 没有评价体系:过程艰苦,很难有结果,但实际上贡献很大
- 选择函数:三个重要参数,w当前等待时间,e当前执行时间,s(期望)服务时间(需估计或给出)
- 决策模型:选择函数考试执行瞬间的处理方式
- 非抢占
- 抢占
- 具体策略:
- \(FCFS(max(w))\):非抢占,最简单的策略,也叫FIFO,大进程占优
- \(Round\ robin(C)\):抢占,即时间片轮转,IO进程吃亏,因为IO中断后进程的时间片就立即结束了;时间片的设置对性能影响很大,大则退化为FCFS,小则进程切换开销大(目前没有最佳策略)
- \(SPN(min(s))\)
- \(SRT(min(s-e))\)
- \(HRRN(max(\frac{w+s}{s}))\):驻留时间越长,越可能被调度
- 虚拟轮转法:在时间片轮转基础上增加多级IO进程等待队列
- 反馈法:每个队列是时间片轮转,若进程未执行完被中断则进入下一个队列;每个队列的时间片递增;这使得CPU分配尽可能公平
- 指数平滑系数\(\alpha\)
- \(S_{n+1}=\alpha T_n+(1-\alpha)S_n\),\(T_n\)表示第n时刻的执行时间,\(S_n\)表示第n时刻服务时间
- 用来预估进程服务的时间\(S_n\)
- \(\alpha\)在0.8时表现比\(\alpha\)在0.5时好;原因:马尔科夫理论
- 性能比较
- 排队论:建模分析系统性能,所有资源都可以抽象为不同的服务员,重要参数\(s,w\),到达分布为泊松分布,其参数为\(\lambda\)。
- ...
- 公平共享调度FSS(Fair Share Scheduler)
- 实际分配的CPU
- 组分配的CPU
- base优先级
- 优先级依赖上三者迭代计算
- UNIX调度
- 在FSS的基础上增加nice,删去group的分配
- 多处理器系统
- 松耦合、分布式多处理器、集群
- 专用处理器:存在主处理器,其它处理器为其服务
- 紧耦合多处理器:共享主存,都由一个OS控制
- 粒度
- 指令:流水线,乱序执行OOD,AVX
- 线程:openMP,pthread
- 进程:MPI
- 程序
- 节点
- 机架
- 集群
- 数据中心
- 多处理器架构
- 主从
- 对等
- 多处理器调度
- ...
- Cache共享:...
- 实时系统
- 硬实时:任务有固定deadline,若失败代价巨大
- 软实时:任务有deadline,在超时后尽力执行完仍然是有意义的
- 很哲学
- 五大特征:
- 确定性:实时系统对外部时间的响应时间是确定的,可重复实现的,不管内部状态如何,都是可预测的;定量:从一个高优先级设备中断到达到开始服务的最大延迟
- 响应性:初始化中断处理和执行中断服务程序需要的时间
- 用户控制:允许用户控制任务优先级
- 可靠性:出错不会崩,或者一个处理机崩可修复
- 故障弱化操作:系统在故障时尽可能多地保存其性能和数据的能力
- 实时调度:...
- 各系统中的多处理器调度
- ...
IO和存储
- IO发展阶段
- CPU直接控制外设
- IO控制器/IO模块
- 中断式IO
- DMA
- IO处理器
- IO处理本地内存,实际上变成了IO处理机;即如今的IO模式,外设有自己的处理器和内存,e.g.smartNZC网卡会自己处理一定的计算,smartDisk磁盘会自己处理一定的计算
- IO速度的提升是慢于CPU性能增长的
- 轮询:IO请求后忙等待IO模块
- 中断IO
- 阻塞:当前进程阻塞,CPU接下来执行OS代码,可能会被调度处理另外的进程
- 非阻塞:CPU接下来执行进程代码
- DMA(Direct Memory Access):直接内存访问
- 架构:一个DMA模块直接控制所有IO模块,DMA和主存通过系统主线直连
- IO模型:多层抽象
- IO缓冲:缓冲是用来平滑IO需求峰值的技术
- 在进程的平均需求大于IO设备的服务能力时,缓冲再多也没用,所有缓冲区都会被填满
- 多道程序缓冲效果模型,因为存在多种进程活动
- 无缓冲:字面意思
- 如DMA
- 单缓冲:数据先放到OS一个系统缓冲池里
- 面向块
- 提前读/预测读
- 缺点:OS设计复杂,影响交换逻辑
- 面向流
- 每次一行
- 每次一个字节
- 面向块
- 双缓存
- 输入,输出各一个
- 循环缓冲
- 多个缓冲
- 分层存储
- 磁盘:详见计组
- 磁道:第几个圈
- 扇区:第几个扇形
- 柱面:哪个盘
- 寻道时间:确定磁道
- 旋转延迟:找扇区&&柱面(柱面其实不用找,因为有多个读写头)
- 访问时间:...
- 磁盘调度算法
- 随机
- FIFO
- RPI:优先级
- LIFO
- SSTF:最短服务时间优先
- SCAN:电梯算法
- C-SCAN:单向电梯算法
- N-SCAN:把请求队列分为几个队列,每个队列分别使用电梯算法
- FSCAN:两个对列,一个初始为空,新请求放入其中,另一种用电梯算法直至空时两队列交换
- RAID:详见计组
- 设计三角:性能(速度)、可靠(纠错&&备份)
- ...
- Cache:详见计组
- 算法:最近最少使用、最不常使用、基于频率
- UNIX
- 成功的抽象:IO系统作为文件系统的子系统
- 支持的硬件:cache、DMA
- 自由链表:记录cache中空闲的信息
- 设备链表:记录buffer和设备的关联关系
- 设备IO队列:记录特定设备的运行和等待信息
- Linux
- 改进的电梯算法,含deadline和预调度
- ...
- 固态盘Flash
- 随机存储读写性能远远优于磁盘
- 磁盘渐渐淘汰
- 多种硬件比较见计组
文件系统
- 基本概念
- Field
- 基本的数据元素
- 单一值
- 定长或变长
- Record
- 相关Field的集合
- 定长或变长
- File
- 相关Record的集合
- 被当做一个单独元素处理
- 可以通过名字引用
- 含访问权限控制
- Field
- 架构
- 由低到高
- 硬件、设备驱动
- 基本文件系统/物理IO:处理块
- 基本IO管理程序:处理多种设备,调度,buffer等
- 逻辑IO:处理记录
- 多种文件结构,如顺序,索引等,处理如何存放记录
- 用户程序
- 记录是文件系统和操作系统交互的接口

- 文件结构
- pile/堆:变长记录集合,按照数据到达顺序组织。目的仅仅是为了保存数据。访问效率很低,爆搜。
- 顺序:定长记录集合,有固定的格式。能简单地被磁盘磁带存储。访问慢,爆搜。
- 索引顺序:底层是顺序文件,但拥有多层索引来支持随机访问。
- 索引:变长记录集合,文件仅能通过索引访问,有多个索引。
- 散列:定长记录集合,很快
- B树:详见数据库
- B+树:详见数据库
- 文件目录
- 文件属性
- 操作:增删改查
- 树结构
- 软链接:一个文件存放的是另一个文件的路径,删软链接,文件不变
- 硬链接:一个文件存放的是另一个文件的索引/引用(inode),删硬链接,文件也被删除
- 文件共享和文件权限
- ...
- 记录组块策略
- ...
- 辅存管理/文件分配
- 分配文件的辅存(磁盘)空间
- 预分配、动态分配
- 预分配很容易产生浪费,但局部性更好
- 动态分配的实现:链式、索引
- 效率
- 单个文件的效率
- 整个系统的效率
- 分区大小
- 一般固定块的大小
- 磁盘一个分区内是连续存储的,区小影响局部性
- 区小管理开销大(FAT表大)
- 区小减少区内浪费
- 也可以使用可变快大小,提供更好的性能,文件分配表也可能会小,但灵活性很差
- 空闲空间管理
- 位表bitmap:每块一位表示,1使用,0空闲
- 链式空闲区:比位表慢
- 空闲块列表:...
- 卷:逻辑存储设备,物理上的扇区组
- UNIX
- 文件类型
- 一般文件:存数据
- 目录:一系列文件及其inode指针
- 特殊文件:与设备交互的接口,即设备是被抽象为一个文件进行管理的
- 命名管道:通信使用
- 硬链接
- 软链接/符号链接
- inode
- 存放文件的核心控制信息
- 一些属性:模型,所有者,时间戳,大小,块大小...
- 访问:直接索引块地址/间接索引指针/多级索引指针
- 卷结构
- boot
- 超级块:存放文件系统信息
- inode表:inode信息集合
- 数据块
- VFS:虚拟文件系统
- 设备被抽象为文件,统一管理磁盘,鼠标等
- 同时需要管理inode和目录
- Linux文件命令
- 文件类型权限查看:ls -l。第 1 个字符表示文件类型,其中,普通文件 (-)、目录文件 (d)、套接字文件 (s),管道文件 (p),字符文件 (c),块文件 (b),链接文件 (l)。然后9位权限位,每3位分别表示所有者权限,所有者同组用户权限,陌生人权限;读(r),写(w),进入目录(x)(只对目录文件有意义)。编一例-rwxr-x--x表示一个所有者可以各种操作,所有者同组用户可以读和进入,陌生人只能进入的普通文件。每3位也可以用3个位来表示,该例子表示为751。
- 块大小:ls -s
- inode:ls -i
- 文件类型
- Windows
- 早期使用FAT32:空间太小
- NTFS
- 日志
- 容错和恢复
- 安全
- 大文件
- 压缩
- 多数据流并发
- 卷结构
- 结构层次:扇区,Cluster(独有的),卷
- boot
- 主文件表:类似超级块
- 文件系统
- 数据区
- Android
- 参考嵌入式文件系统组织
- 简化版的linux
- 组织结构:/system目录只读
- SQLite:文件系统类似数据库,轻量
操作系统笔记
http://example.com/2021/12/06/操作系统笔记/